UTXO Stack Data Availability Layer
Data Availability (DA) layer solves the data availability problem in a trust-minimized way by leveraging the data availability sampling protocol.
The UTXO Stack DA layer leverages light clients to perform data sampling. Therefore, light client nodes constantly sample data shares from full nodes and broadcast shares if they are valid. If there are enough light clients in the network, we can be confident that an honest full node can collect enough shares to reconstruct the full data.
UTXO Stack and RGB++ provide an exit strategy in case of a DA attack, as detailed in the DA exit documentation. Although the asset security does not depend solely on the security of the DA layer, using the DA layer still has some advantages:
-
Increases the cost of malicious attacks: Attackers must simultaneously attack the DA layer and the branch chain to manipulate assets.
-
Reduces the cost of challenges: The DA layer supports data retrieval through light clients and data availability sampling (DAS), which significantly lowers the cost of running a challenge node. This approach not only makes it more economical to maintain challenge nodes but also enhances the overall security and reliability of the network by making it easier for more participants to engage in the challenge process.
-
Concentrates staking: All branch chains's staked value comes from the DA layer. The combined staking value from all branch chains contributes to the security of the DA layer, creating a more robust and resilient system.
DA chain
Header
The DA chain uses a similar architecture to the branch chain, but extends the consensus mechanism and P2P network protocols to support the DA layer functionality.
The DA chain's block structure is consistent with the branch chain. However, the meaning of the tx_root field has changed. In the DA chain, the new field da_tx_root is calculated from the tx_root and the tx_blob_root using merkle_hash(tx_root, tx_blob_root). This modification allows the DA chain to generate Merkle proofs for blobs, which are used in data sampling and data submission verification.
// branch chain
let tx_root = merkle_hash(txs);
// DA chain
let tx_root = merkle_hash(txs);
let tx_blob_root = merkle_hash(txs.map(|tx| merkle_hash(tx.blobs)))
let da_tx_root = merkle_hash([tx_root, tx_blob_root]);
The P2P message protocol is extended to additionally broadcast the list of Blobs contained in the Block when transmitting the Block. DA chain validators must wait to receive the complete Block and the complete Blobs before verifying the da_tx_root. If everything is valid, they can then continue to verify and sign the block.
Submit data
The DA chain has a built-in Dummy Type ID - Data Store in the Genesis, which is used to mark whether a transaction has submitted Blobs. The Data Store rules are verified by the consensus.
If a DA chain transaction submits data, the first output's type_script must use the Data Store contract, and the output's cell data field must be the 32-byte merkle_hash(blobs).
Branch chain consensus nodes utilize the submit_tx_with_blobs interface when submitting chain data (e.g. branch chain transactions), along with the blobs list. The DA validators will check if the Blobs submission information is consistent with the related transaction, and if so, they will broadcast the transaction and Blobs.
DA validators thoroughly verify each block by calculating the blob_root for each transaction and comparing it to the da_tx_root. If any discrepancies are found, the block is rejected.
The Blob structure is as follows:
pub struct Blob {
version: u32,
data: Bytes,
}
pub struct TxWithBlob {
tx: Tx,
blobs: Vec<Blob>
}
DA proof
After a DA chain transaction is packaged, branch chain nodes can provide a Merkle proof based on the da_tx_root in a block header to cryptographically prove that a specific blob has been submitted to the DA chain:
- The branch chain block header must save the Merkle root of the submitted blobs -
da_blobs_root. - After the DA Chain has packaged the blobs, one can obtain the DA chain block header and the Merkle proof for the da_blobs_root.
- An on-chain DA light client on CKB can be invoked to verify the Merkle Proof, to prove that the branch chain data has been submitted to the DA layer.
Pruning
DA chain Nodes with pruning enabled will periodically delete block and blob data, keeping only the block headers. This saves significant disk space. Nodes can be set to "archive mode" to persist the full data.
Data availability sampling
Data availability sampling (DAS) is a crucial technique used by the DA chain to ensure the availability and retrievability of block data and blobs.
DA chain nodes use Reed-Solomon erasure coding to split the block data and blobs into multiple shares. These shares are organized into a 2D matrix structure using a 2D Reed-Solomon Encoded Merkle tree. This generates the dataRoot of each row and column in the 2D matrix.
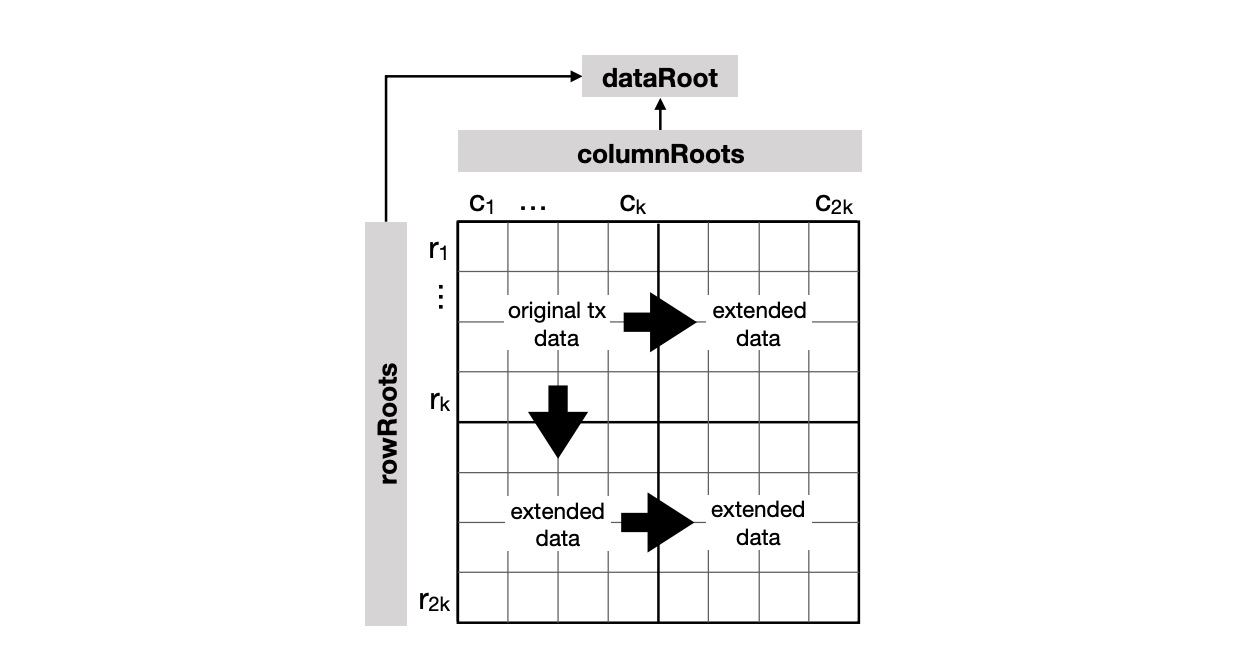
The DA chain light clients randomly select a set of coordinates to query shares from full nodes. If the full nodes return valid shares, it indicates that the data is most likely available. They continuously request shares from the DA chain full nodes and propagate them through the P2P gossip protocol.
As a result, honest full nodes have a high probability of obtaining enough shares (i.e., at least 𝑘×𝑘 unique shares) from the P2P network to recover the complete data.